Analyzing Amazon Reviews, Textual Metrics, and User’s Perceived Helpfulness
This study analyzes factors influencing review helpfulness using the Amazon Review/Product Dataset, focusing on Cell Phones and Accessories and Video Games categories with advanced text analysis and modeling techniques.
Background
Online reviews significantly influence consumer purchasing decisions by providing insights into product quality. The Amazon Review/Product Dataset, provided by Julian McAuley and Jianmo Ni from UCSD, contains 233.1 million reviews from May 1996 to October 2018. This project examines the "Cell Phones and Accessories" and "Video Games" categories to identify how features like writing style and media elements correlate with helpfulness votes, using tools like LIWC and LDA.
Research Question
How do review writing style, length, readability, balance, breadth, verified purchase status, number of entities, and presence of images affect the perceived helpfulness (votes) of Amazon reviews in the Cell Phones and Accessories and Video Games categories?
Hypothesis
“Features such as analytical writing style, optimal review length, readability, balanced sentiment, topic breadth, verified purchase status, number of entities, and presence of images will exhibit varying correlations (positive, negative, or curvilinear) with helpfulness votes, with specific thresholds optimizing impact.”
This is informed by research on content richness and authority cues in online reviews.
Dataset
The Amazon Review/Product Dataset from UCSD includes 233.1 million reviews from May 1996 to October 2018. This project focuses on 'Cell Phones and Accessories' (1,128,437 review rows, 590,071 metadata rows) and 'Video Games' (231,780 review rows, 84,819 metadata rows), with review data (e.g., text, votes) and metadata (e.g., price, brand). These are raw data figures before cleaning.
Data Cleaning, Pre-processing, and EDA
JSON files were converted to Python dataframes. Duplicates were removed to avoid data contamination. Review and metadata were merged using ASIN numbers.
Unimportant columns and rows with NaN or numeric values in 'reviewText' were dropped. NaN votes were replaced with zero. Post-cleaning, Cell Phones and
Accessories had 1,041,169 rows and 18 columns, while Video Games had 28,133 rows and 28 columns.
EDA processed 'reviewText' by extracting sentence count, removing stopwords and numbers, converting to lowercase, applying lemmatization, and calculating word
and unique word counts. The 'rank' column was mined to extract product rank and category/sub-category names for enhanced feature analysis.
Linguistic Inquiry and Word Count (LIWC) - 22
LIWC-22 is a text analysis software that gives more profound insights into the words in the corpus. When applied on the dataset, it gives 118 features for any review, such as Authentic, Emotional Tone, Past Focus, etc. In order to calculate these statistics, each dictionary word is measured as a percentage of total words per text (Cronbach’s α) or, alternatively, in a binary “present versus absent” manner (Kuder– Richardson Formula 20; Kuder & Richardson, 1937).
Topic Modeling using LDA
Feature Extraction
The following features were extracted from the Amazon Review/Product Dataset to analyze their impact on perceived helpfulness (votes). Extraction methods leveraged text processing, LIWC, NER, and topic modeling techniques, as detailed below:
- Review Writing Style (Analytic): This feature was extracted using the LIWC-22 "Analytic" summary variable, which quantifies logical and formal thinking in text. Each review’s text was processed by LIWC to produce a score (0-100), where higher scores indicate structured, analytical writing (e.g., using articles and prepositions), and lower scores reflect a narrative style.
- Review Length (WPS): Review length was calculated as Words Per Sentence (WPS) by dividing the total word count by the sentence count in each review’s "reviewText." Both metrics were derived using LIWC’s built-in word and sentence segmentation, providing a measure of review verbosity.
- Review Readability (FRE): Readability was assessed with the Flesch Reading Ease (FRE) index, computed as FRE = 206.835 - (1.015 * Avg. words per sentence) - (84.6 * Avg. syllables per word). Average words per sentence and syllables per word were extracted from "reviewText" using text processing tools, yielding a score where higher values indicate easier comprehension.
- Review Balance: This was measured as the ratio of LIWC’s positive tone (tone_pos) to negative tone (tone_neg) variables. Both tones were extracted as percentages of words reflecting positive or negative sentiment in each review, providing a balance metric to assess sentiment neutrality or bias.
- Review Breadth: Breadth was determined using Latent Dirichlet Allocation (LDA) topic modeling with k=7 topics. The "reviewText" was processed to assign topic probabilities, and the count of topics with probabilities above a 0.05 threshold was calculated as Total Important Topics, reflecting the diversity of subjects covered.
- Verified Purchase: Extracted directly from the dataset’s "verified" field, this binary feature was coded as a dummy variable (1 = TRUE for verified purchase, 0 = FALSE), indicating whether the reviewer purchased the product on Amazon.
- Number of Entities: Named Entity Recognition (NER) via the spaCy library was applied to "reviewText" to identify and count entities (e.g., product names, brands, locations). The total entity count per review was recorded as a measure of informational detail.
- Review with Image: This feature was derived from the "image" field in the dataset, coded as a dummy variable (1 = image URL present, 0 = absent), indicating whether a review included user-uploaded images alongside text.
Graphs and Plots
Below are visualizations illustrating key insights from the analysis of review helpfulness.
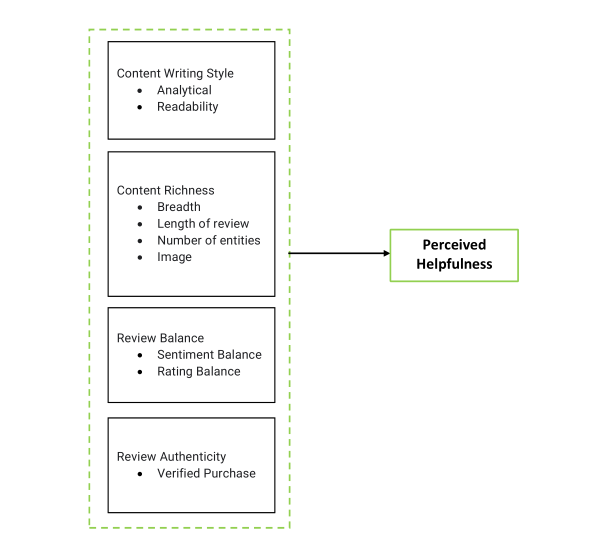
Figure 1: Perceived Helpfulness Model

Figure 2: Word Cloud for Cell Phones and Accessories Reviews shows terms like 'phone,' 'review,' 'screen,' 'nokia, 'android,' etc.
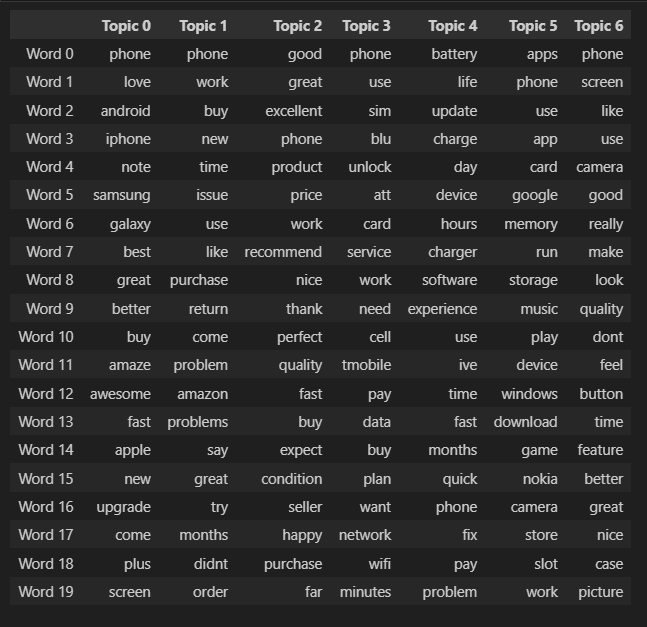
Figure 3: The promiment words which represent each of the 7 topics

Figure 4: Probability Distribution among the 7 topics and calculation of Dominant and Total Important Topics
Model and Findings
Features affecting perceived helpfulness (votes) include:
- Review Writing Style (Analytic): LIWC’s Analytic score (0-100) measures logical thinking; higher scores positively correlate with votes, enhancing trust and clarity.
- Review Length (WPS): Words per sentence shows a curvilinear relationship; moderate lengths optimize helpfulness, while extremes reduce it.
- Review Readability (FRE): FRE exhibits a curvilinear relationship; moderate readability balances simplicity and depth, maximizing votes.
- Review Balance: Ratio of positive to negative tone is curvilinear; balanced reviews (acknowledging pros and cons) are deemed most helpful.
- Review Breadth: Topic count via LDA is curvilinear; moderate topics provide depth without confusion, boosting helpfulness.
- Verified Purchase: Dummy variable (1 = TRUE, 0 = FALSE) positively correlates with votes, indicating higher credibility.
- Number of Entities: NER count positively correlates with votes; detailed entity mentions enhance informativeness.
- Review with Image: Dummy variable (1 = with image, 0 = without) highly positively correlates with votes, adding visual credibility.
Conclusion
This study reveals that review helpfulness is influenced by multiple factors. Analytical writing style (positive correlation) enhances clarity and trust, with higher LIWC Analytic scores linked to more votes. Review length (curvilinear) peaks at moderate lengths, avoiding extremes of brevity or verbosity. Readability (curvilinear), measured by FRE, optimizes at a balance between simplicity and depth. Review balance (curvilinear) favors nuanced perspectives over biased tones. Review breadth (curvilinear), via LDA with k=7, benefits from moderate topic coverage. Verified purchase status (positive) and number of entities (positive) boost credibility and informativeness. Reviews with images (highly positive) add visual proof, significantly increasing votes, though relevance is key. These findings suggest that content richness, authority, and multimedia cues are critical drivers of perceived helpfulness, with optimal thresholds enhancing model predictions for vote counts.
References
1. Xu, K., & Zhang, C. (2018). Content richness in social media.
2. Pennebaker, J. W., et al. (2015). Writing style and engagement.
3. Choi, W., & Stvilia, B. (2015). Writing styles and impressions.
4. Zheng, L., et al. (2021). Information seeking in risky situations.
5. Liu, F., et al. (2014). Rumor retransmission in disasters.
6. Allport, G. W., & Postman, L. (1947). Psychology of rumor.
7. Analytics Vidhya. (2022). Text cleaning methods in NLP.
8. Analytics Vidhya. (2021). Topic modeling in NLP.
9. DZone. (n.d.). Topic modeling techniques and AI models.
10. Stack Overflow. (n.d.). Determining number of topics for LDA.
11. Neptune.ai. (n.d.). pyLDAvis topic modeling tool.
12. Ni, J., Li, J., & McAuley, J. (2019). Justifying recommendations using distantly-labeled reviews. EMNLP-IJCNLP.