Evaluating Psychometric Features and Contextual Embeddings for Mental Disorder Classification
This study assesses the potential of psychometric features and contextual embeddings to classify mental disorders (anxiety, panic, depression) in short biomedical texts from social media, using machine learning and deep learning models.
Background
Mental health, encompassing emotional, psychological, and social well-being, significantly impacts daily life, physical health, and relationships. With the rise of social media, user-generated content provides a valuable resource for detecting mental disorders like anxiety, panic, and depression. Despite growing awareness, these conditions remain underdiagnosed due to stigma and complexity. This study leverages natural language processing (NLP) to analyze short biomedical texts from Reddit (where individuals openly discuss their experiences), addressing the gap in simultaneous classification of anxiety, panic, and depression, and exploring how psychometric features and contextual embeddings can enhance early detection/diagnosis and treatment.
Research Question
How can psychometric features (e.g., LIWC, Emotions, Emotional Intensity) and contextual embeddings be combined to effectively classify mental disorders (anxiety, panic, depression) in short biomedical texts from social media?
Hypothesis
“Psychometric features (LIWC, emotion detection, emotion intensity) and contextual embeddings (SBERT) can be effectively combined using machine learning and
deep learning models to achieve high accuracy in classifying anxiety, panic, and depression in short biomedical texts from social media, outperforming models
using individual feature sets.”
This hypothesis is based on prior research suggesting that combining semantic (contextual embeddings) and psychological and psychometric features information
enhances mental health classification, as these features capture both linguistic patterns and emotional nuances in text.
Dataset
The study collects data from Reddit, leveraging its specialized mental health subreddits to obtain user-generated posts related to anxiety, panic, and depression (as detailed in Table 3.1 of the report). Data was scraped using Apify, a web scraping tool capable of extracting up to 1000 posts per subreddit, ensuring efficiency and compliance with website policies. Only original posts were collected, excluding comments, to maintain comprehensive and self-contained descriptions of mental health experiences. Broad subreddits like r/mentalhealth and r/anxietydepression were excluded to avoid ambiguity in labeling. This dataset comprises 7,866 unique posts, forming a rich textual corpus for feature extraction and psychometric analysis.
The data cleaning process ensured high-quality input for analysis by removing duplicates, checking for missing values, and filtering texts based on length. Two duplicate rows were eliminated to prevent redundancy, and no missing values were found. Texts with fewer than 10 words were removed to ensure meaningful context, while texts exceeding 1024 words were excluded to maintain compatibility with transformer-based models. The dataset was labeled into three categories—anxiety, panic, and depression—based on the source subreddits. To address class imbalance, undersampling was applied, reducing the majority classes to match the minority class, resulting in a balanced dataset with approximately 1,812–1,815 rows per category. This resulted in a final balanced dataset of 5,441 rows, ensuring better generalization and model reliability.
Subreddit Posts Example

Methodology
This study employed a structured pipeline involving data collection and pre-processing, feature extraction, and model evaluation to classify mental disorders in short biomedical texts.
Feature Extraction
-
Contextual Embeddings: After experimenting with multiple BERT-based models such as
bert-base-nli-mean-tokensfromHuggingFace,all-distilroberta-v1underSentenceTransformerswas chosen for subsequent experiemnts as it yielded the best results in terms of classification performance. - Linguistic Inquiry and Word Count (LIWC) - 22 Features: The text analysis software LIWC quantifies linguistic and psychological features, with 118 features measuring aspects like lifestyle, family, work, culture, money, and illness. Summary measures analyze analytical thinking, clout, authenticity, and emotional tone, with scores ranging from 1 to 99. The tool also provides fundamental statistics like word count and words per sentence.
-
Emotions Detection: Incorporated
EmoRoBERTa, a fine-tuned model based on RoBERTa. It employs multi-label classification, assigning multiple emotion labels to a single text, reflecting the complexity of human emotions. The model outputs 28 probability scores, summing to 1, representing emotions such as amusement, caring, realization, nervousness, optimism, etc. - Emotion Intensity: Emotion intensity measures the strength of emotions expressed in text, where words like "miserable" convey stronger feelings than "sad." Using the NRC Emotion Intensity Lexicon (NRC-EIL), which contains 9,829 words with intensity scores from 0 to 1, the approach evaluates eight basic emotions—anger, anticipation, disgust, fear, joy, sadness, surprise, and trust. Texts are converted to lowercase, and intensity is calculated as the mean score of identified words.
Model Development and Evaluation
Developed and compared Logistic Regression (LR), Extreme Gradient Boosting (XGB), and a Multi-layered Deep Learning architecture (LSTM + CNN, LSTM + CNN + LSTM, etc.) using 10-fold cross-validation. Evaluated models with metrics like accuracy, F1 score, and Matthews Correlation Coefficient (MCC).
Results and Findings
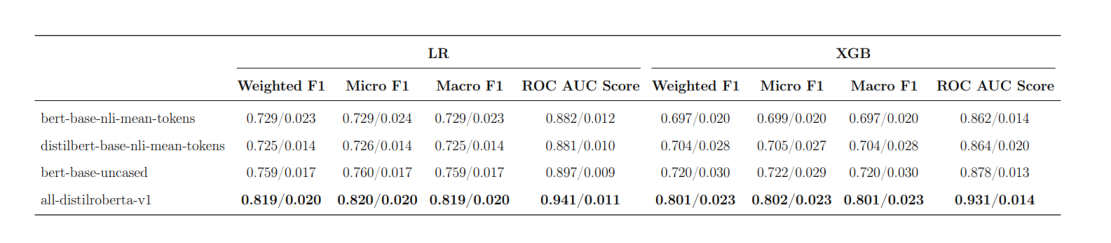
- Logistic Regression (LR): Achieved the highest weighted F1 score of 81.9% when combining sentence embeddings with emotions, outperforming other configurations.
- Extreme Gradient Boosting (XGB): Reached an weighted F1 score of 80.3% when embeddings, normalized LIWC features, and emotions were combined, with strong performance but slightly lower than LR.
- Deep Learning (LSTM + CNN): Obtained an F1 score of 80.7% with LSTM(32) + CNN(5,2), showing competitive results but highlighting challenges in modeling nuanced mental health texts.
- Feature Impact: Combinations of contextual embeddings, emotions, and intensity outperformed LIWC features alone, with normalized LIWC improving performance when integrated with embeddings.
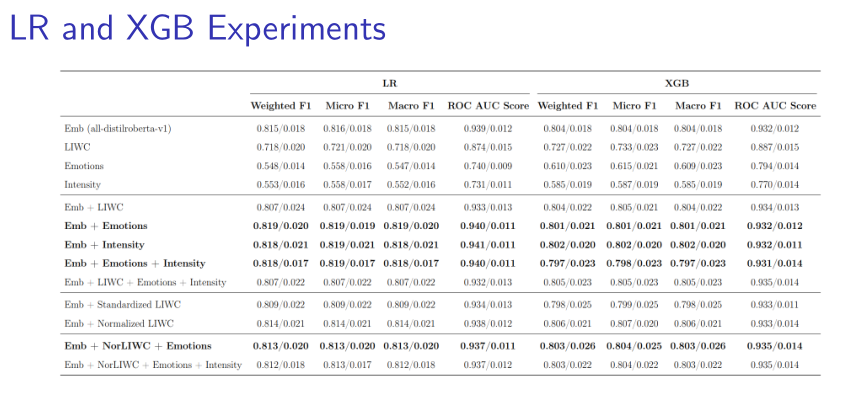
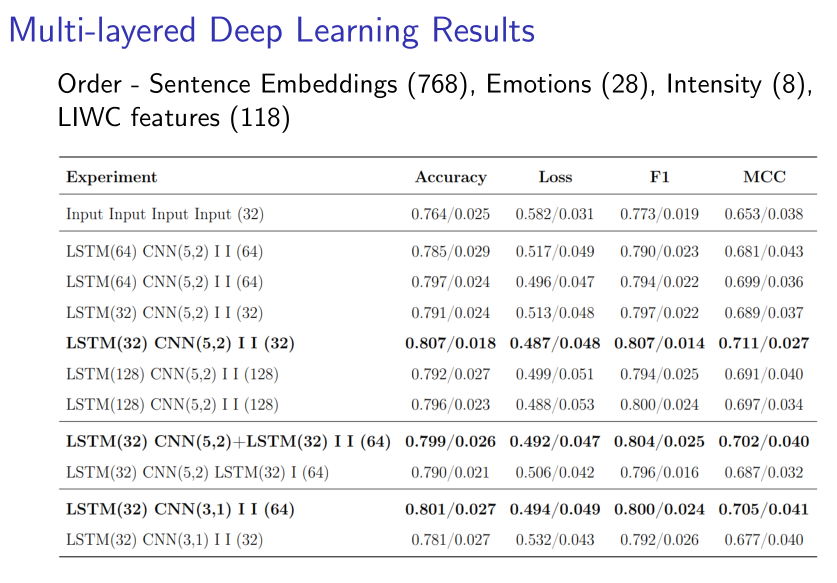
These findings suggest that psychometric features and contextual embeddings are powerful for mental disorder classification, with LR being the most effective model for this dataset.
Graphs and Plots
Below are visualizations illustrating key insights from the analysis of mental health classification.
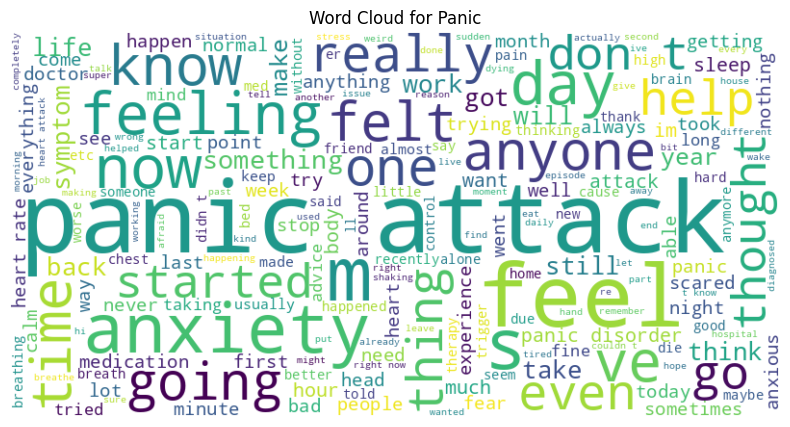
Figure 1: Word Cloud for the Panic Dataset
Highlights frequent terms like ”panic,” ”attack,” ”feel,” ”heart,” ”time,”
”help,” ”anxiety,” and ”breath,” reflecting common themes in mental health posts.
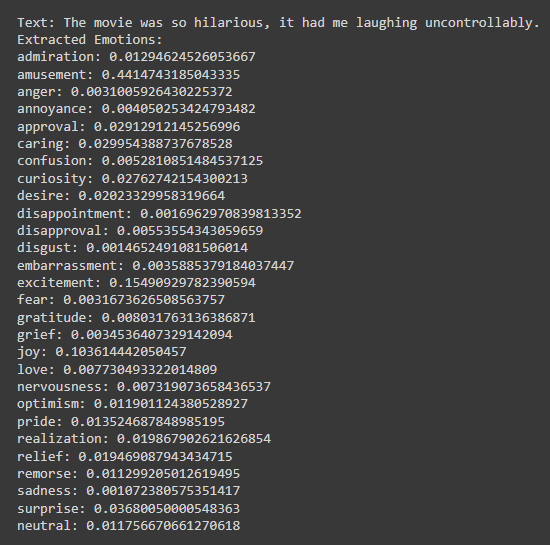
Figure 2: Emotion Extraction of a positive text
Shows high probabilities of emotions such as amusement (0.44), excitement (0.15), and joy (0.10).
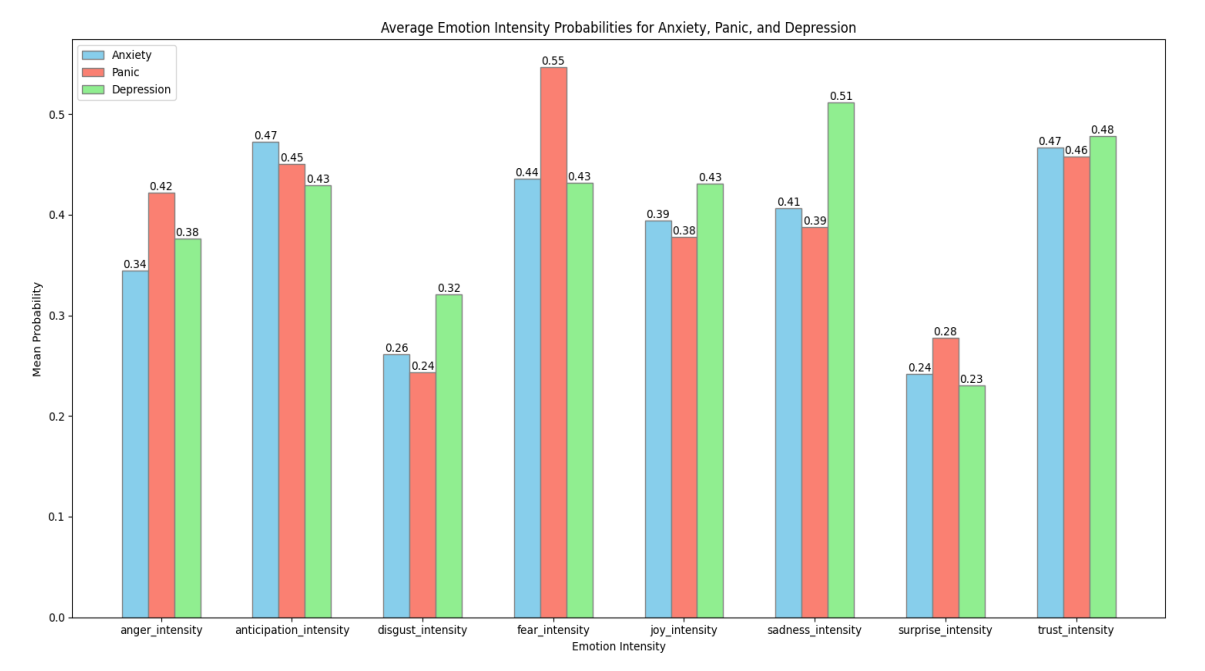
Figure 3: Average Probabilities of Emotional Intensities for anxiety, panic, and depression datasets
Anger intensity is highest in the panic dataset at 0.42, indicating that panic
attacks may evoke anger due to sudden loss of control, followed by depression at 0.38 and anxiety at 0.34, possibly reflecting frustration or irritability. Anticipation intensity peaks in the anxiety dataset at
0.47, showing heightened worry about future events, with panic at 0.45 and depression at 0.43, suggesting a general lack of optimism across all three conditions.
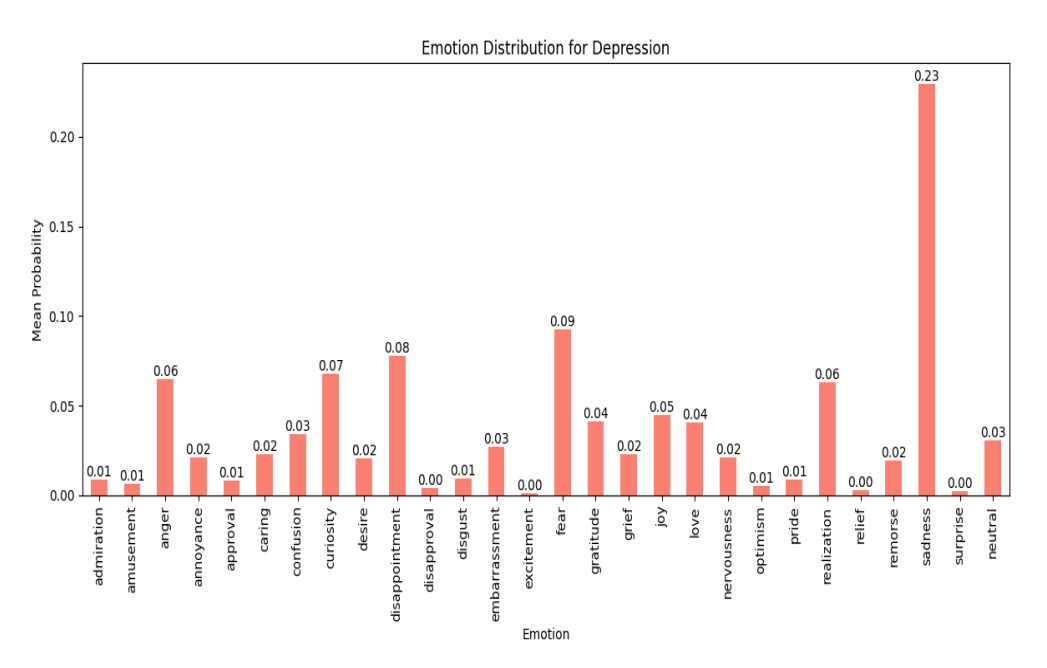
Figure 4: Average Probabilities of Emotions for Depression dataset
Sadness (0.23) is the most dominant emotion, reflecting the sorrow and hopelessness associated with depression.
Fear (0.09) indicates underlying worries, while disappointment (0.08) highlights frustration from unmet expectations. Realization (0.06) suggests moments of clarity or self-awareness within the depressive state.
Conclusion
This study demonstrates that psychometric features (LIWC, emotions, intensity) and contextual embeddings can effectively classify anxiety, panic, and depression in short biomedical texts from social media, with Logistic Regression achieving the best performance (F1 score of 81.9%). The results highlight the potential of NLP for early mental health detection, reducing stigma, and improving outcomes, while suggesting future work on larger datasets, along with hyperparameter tuning, and incorporating Large Language Models (LLMs) for deeper insights and causal inferencing.
References
1. Prince, M., et al. (2007). No health without mental health. The Lancet, 370(9590), 859–877.
2. Calvo, R. A., et al. (2017). Natural language processing in mental health applications using non-clinical texts. Natural Language Engineering, 23(5), 649–685.
3. Rissola, E. A., et al. (2020). A dataset for research on depression in social media. Proceedings of the 28th ACM Conference on User Modeling, Adaptation and Personalization, 338–342.
4. Kim, J., et al. (2020). A deep learning model for detecting mental illness from user content on social media. Scientific Reports, 10(1), 11846.
5. Mitrović, S., et al. (2023). Annotating panic in social media using active learning, transformers and domain knowledge. 2023 IEEE International Conference on Data Mining Workshops (ICDMW), 1269–1278.